OpenAI: Feinjustierte Version von GPT-3 soll Nutzer-Anweisungen besser umsetzen
[ad_1]
Toxische Sprache, Beleidigungen, Fehlinformationen und sachliche Ungereimtheiten gelten als Risiken bei großen Sprachmodellen (LM), die einen großteils aus dem Internet bezogenen Textcorpus umfassen und dabei das Beste, aber auch das Schlechteste menschlicher Äußerungen zunächst unterschiedslos aufsaugen (und entsprechend auch wiedergeben können). OpenAI hat nun eine neue Version von GPT-3 vorgestellt, die gezielte Anpassungen durchlaufen haben soll, um die Anweisungen ihrer Nutzer besser umzusetzen und weniger toxischen Output zu liefern. InstructGPT heißt die gezähmte Ausgabe des großen Sprachmodells, die in Machine-Learner-Jargon stärker auf die Intentionen ihrer menschlichen Nutzer “aligned” sein, also mit deren Absichten in Einklang stehen soll.
Mit menschlichem Feedback feinjustiert
InstructGPT ist das Ergebnis eines Finetunings von GPT-3, wofür das OpenAI-Team an seinem bislang größten Sprachmodell Reinforcement Learning mit menschlichem Feedback (RLHF) vornahm. Mit 1,3 Milliarden Parametern ist das nachjustierte Modell deutlich kleiner als sein großer Bruder GPT-3, der 175 Milliarden Parameter umfasst. Aus dem Forschungspaper des OpenAI-Teams geht hervor, dass Menschen in der vergleichenden Auswertung eher die Antworten und den Output von InstructGPT bevorzugten und insgesamt als hilfreicher empfanden.
Für das Feinjustieren hatten rund 40 Personen – Labelers genannt – die Antworten von GPT-3 auf teils kreative Textaufgaben bewertet. Die Aufgaben (Prompts) forderten das Modell beispielsweise auf, ein Gedicht über einen klugen Frosch zu schreiben oder einem sechsjährigen Kind die Mondlandung in kindgerechter Sprache zu erklären.


OpenAI: Vergleich zwischen GPT-3 und dem feinjustierten Modell InstructGPT. Das Modell soll die Mondlandung einem sechsjährigen Kind erklären. GPT-3 wiederholt wie eine Suchmaschine die Frage in Variationen, InstructGPT gibt eine zutreffende, eher gewünschte Antwort.
(Bild: OpenAI)
Enthielten die Antworten Gewalt, sexuelle Themen, starke Meinungen oder gruppenbezogene Erniedrigungen, werteten die Mitarbeiter sie ab. In deutlich über der Hälfte aller Fälle (70 Prozent laut Paper des OpenAI-Teams) schnitt am Ende das von Menschen beeinflusste Modell InstructGPT besser ab als GPT-3. Gemessen an gängigen Metriken aus öffentlich verfügbaren Datensätzen imitiert InstructGPT laut OpenAI-Team seltener Unwahrheiten, ist weniger “toxisch” bei den Antworten und “halluziniert” seltener Fakten herbei. Zudem sollen die Outputs insgesamt etwas treffsicherer ausfallen als bei GPT-3 vor der Feinjustierung.
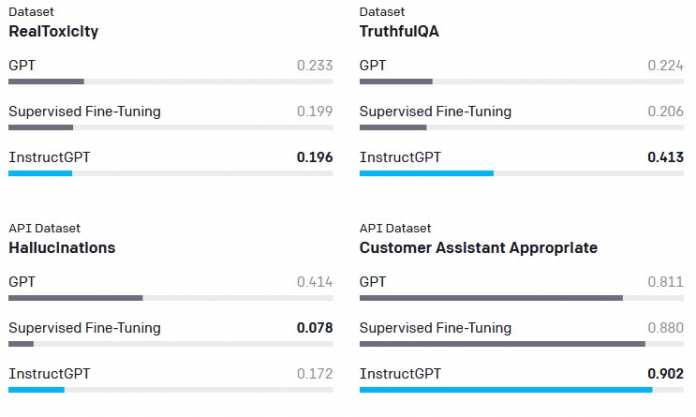
KI-Sicherheit von InstructGPT versus GPT-3 von OpenAI: Metriken im Vergleich
(Bild: OpenAI)
InstructGPT neues Standardmodell für Zugriff über die API
Vorherige Versuche des Alignments waren über Filter gelaufen, die allerdings die Leistungsfähigkeit der Modelle stärker beeinträchtigten, wie ein Mitglied des Alignment-Teams bei OpenAI gegenüber MIT Technology Review erklärte.
Ab sofort ist InstructGPT das Standardmodell hinter der API, über die Interessierte gegen Gebühr das Sprachmodell von OpenAI nutzen können. OpenAI hatte im November 2021 GPT-3 ohne Warteliste über die API zugänglich gemacht. Die größere Vollversion dürfte damit extern nicht mehr greifbar sein. Wer sich für Details interessiert, findet nähere Informationen zu InstructGPT im Blogeintrag bei OpenAI. Dort ist auch das Forschungspaper verlinkt, das die Methoden und Ergebnisse genauer darlegt.
(sih)
[ad_2]



1 Comment
Candyt · June 28, 2024 at 7:56 am
Great write-up! The points discussed are highly relevant. For those wanting to explore more, this link is helpful: FIND OUT MORE. What are your thoughts?